
Senior Applied Scientist @ Amazon AGI
Hello, world!
I am a Senior Applied Scientist at Amazon AGI in NYC. My work focuses on training intelligent systems that can learn new skills with minimal human supervision. Currently, I am a core contributor behind the Amazon Nova foundation models (Amazon Blog, Forbes), focusing on data-efficient pre-training and continuous learning. I also contributed to upgrading Amazon Alexa to chat more naturally while retaining API calling abilities, now available as Alexa+.
I got a Ph.D. in Computer Science at Columbia University, where I was fortunate to be advised by Prof. Luis Gravano and Prof. Daniel Hsu. My PhD research was on Machine Learning and Natural Language Processing (NLP). Specifically, I developed minimally supervised learning frameworks to assist domain experts in teaching neural networks via flexible types of interaction, such as domain-specific keywords, coarse labels, taxonomies, and labeling rules. I have demonstrated the benefits of high-level supervision for scaling NLP across domains, languages, and tasks, including knowledge graph construction, sentiment analysis, cross-lingual learning, and mining social media for rare events related to public health (The New York Times, The Washington Post).
In a previous life, I worked on human emotion recognition from conversational speech data, music information retrieval, and training multimodal word embeddings to ground language to the visual and auditory sense modalities. Aside from research, I love playing the bass guitar, windsurfing, taking photos and drone shots, and traveling. I grew up in Sitia, a small town in eastern Crete that produces delicious tsikoudia and has wonderful places around! Here are a few of my drone shots: Vai Palm Beach, Tenda Beach.
For more information about me, see my CV or contact me.
Education


Professional Experience



For more details, please see my full CV (PDF).
News
Projects
Information Extraction from Social Media for Public Health
Joint work with Tom Effland and Lampros Flokas
Advised by Luis Gravano and Daniel Hsu
We have been collaborating with health departments in NYC and LA on processing social media data for public health applications.
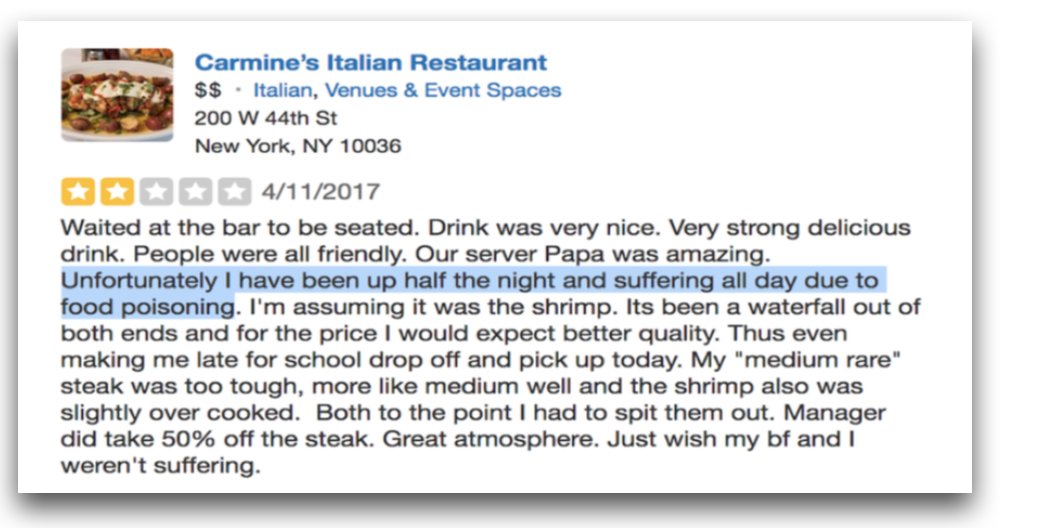
We have deployed systems that help DOHMH track user complaints on social media (e.g., Yelp reviews, tweets) and detect foodborne illness outbreaks in restaurants.
We have developed a weakly supervised network, HSAN, which highlights important sentences in "Sick" reviews as an effort to facilitate inspections in health departments. We have also built models for foodborne illness detection in languages beyond English and have analyzed how Yelp reviews have changed during the COVID-19 pandemic. For more information, check our papers.
Training Neural Networks with Domain-Specific Rules
Work with Microsoft's Language and Information Technologies (LIT) team
Advised by Subho Mukherjee, Guoqing Zheng, and Ahmed Awadallah
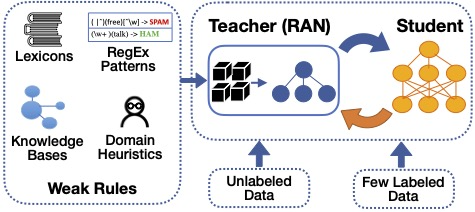
State-of-the-art deep neural networks require large-scale labeled training data that is often expensive to obtain. During my internship at Microsoft Research, we developed ASTRA, a semi-supervised learning framework for training neural networks using domain-specific labeling rules (e.g., regular expression patterns). ASTRA leverages multiple heuristic rules through a Rule Attention Network (RAN Teacher) and automatically generates weakly-labeled data for training any classifier (Student) via iterative self-training.
[Microsoft page] [NAACL '21 paper] [ASTRA Code]
Document Classification Across Languages With Minimal Resources
Advised by Luis Gravano and Daniel Hsu
While most NLP models and training datasets have been developed in English, it is important to consider more languages out of the 4,000 written languages in the world. However, it would be expensive or sometimes impossible to obtain training data across all languages for deep learning. In our recent work, we show how to train neural networks for a target language without labeled data. We developed CLTS, a method for transferring weak supervision across languages using minimal resources. CLTS sometimes outperforms more expensive approaches and can be applied even for low-resource languages!
[LOUHI@EMNLP '20 paper] [Findings of EMNLP '20 paper] [Slides]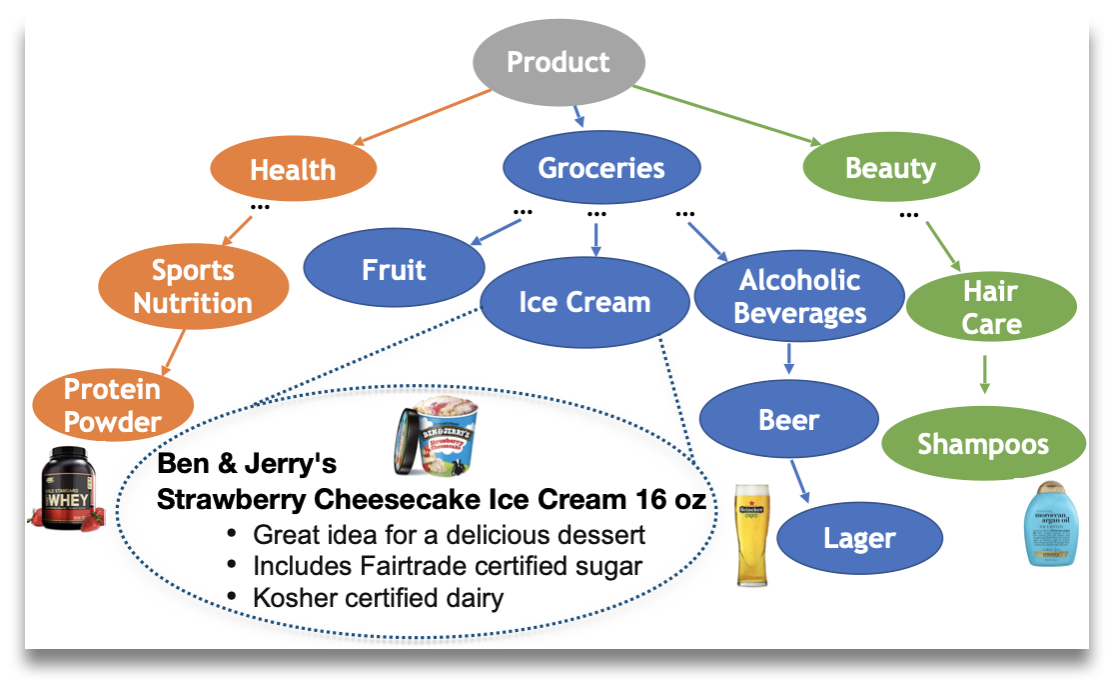
Knowledge Graph Construction for Products from 10K+ Categories
Work with Amazon's Product Graph Team
Advised by Xin Luna Dong and Jun Ma
Product understanding is crucial for product search at Amazon.com or answering user's questions through Amazon's Alexa (personal assistant): ``Alexa, add a family-size chocolate ice cream to my shopping list.'' During my internship at Amazon, we worked on the construction of a knowledge graph of products or "product graph". To scale up to a taxonomy of thousands of product categories without manual labeling, we developed TXtract, a taxonomy-aware deep neural network that extracts product attributes from the text of product titles and descriptions (ACL'20 paper). TXtract is an important component into "AutoKnow", Amazon's large-scale knowledge graph of products (KDD'20 paper).
[blog] [TWIML podcast] [ACL '20 paper] [KDD '20 paper] [Slides]
Training Classifiers with Keywords Via Weakly Supervised Co-Training
Advised by Luis Gravano and Daniel Hsu
We have been developing deep learning models that annotate online reviews (e.g., Amazon product reviews, Yelp restaurant reviews) with aspects (e.g., price, image, food quality). Manually collecting aspect labels for training is expensive, so we propose a weakly supervised learning framework, which only requires from the user to provide a few descriptive keywords (seed words) for each aspect (e.g., 'price', 'value', and 'money' for the Price aspect). To leverage keywords in neural networks, we developed "Weakly-Supervised Co-Training", a teacher-student approach that uses keywords in a teacher classifier to train a student neural network (similar to knowledge distillation) and iteratively updates the teacher and student (EMNLP'19 paper).
[LLD@ICLR '19 paper] [EMNLP '19 paper] [slides]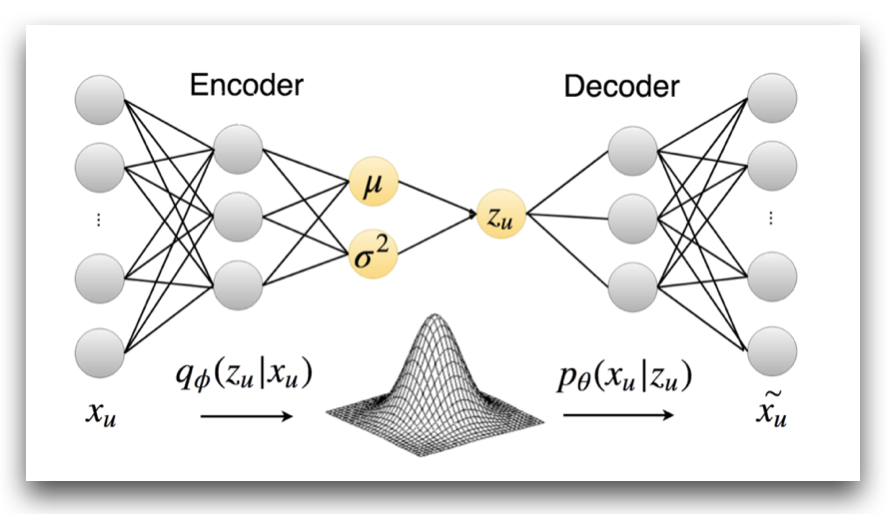
Deep Learning for Personalized Item Recommendation
Joint work with Kevin Cherian and Ananth Narayan
Advised by Tony Jebara
We developed deep learning models for recommending items (e.g., restaurants, movies) to users in online platforms. In our recent paper, we show how to extend Variational Autoencoders (VAEs) for collaborative filtering with side information in the form of user reviews. We incorporate user preferences into the VAE model as user-dependent priors.
[link] [DLRS@RecSys '18 paper] [slides]Transfer Learning for Style-Specific Text Generation
Joint work with Katy Ilonka Gero
We trained deep language models (LSTMs) for generating text of a specific literary style (e.g., poetry). Training these models is challenging, because most stylistic literary datasets are very small. In our paper, we demonstrate that generic pre-trained language models can be effectively fine-tuned on small stylistic corpora to generate coherent and expressive text.
[link] [ML4CD@NIPS '18 paper]
"Sobrite" Mobile Health App
Joint work with John Bosco, Mark Chu, Lampros Flokas, and Fatima Koli
We developed a mobile app that is powered by Machine Learning and provides holistic tools to patients receiving treatment from opioid addiction, as an effort to help them maintain sobriety beyond formal treatment. We were one of the winning teams in the "Addressing the Opioid Epidemic" challenge (Columbia Engineering, 12/2017).
[link] [Android app] [iOS app]
NAO Dance! CNNs for Real-time Beat Tracking
Joint work with Myrto Damianou, Christos Palivos, and Stelios Stavroulakis
Advised by Aggelos Gkiokas and Vassilis Katsouros
We embedded real-time beat tracking and music genre classification algorithms into the NAO humanoit robot. While music plays, NAO's choreography dynamically adapts to the genre and the dance moves are synchronized with the output of the beat tracking system. We submitted our system to the Signal Processing Cup Challenge 2017.
[demo] [ISMIR '17 paper]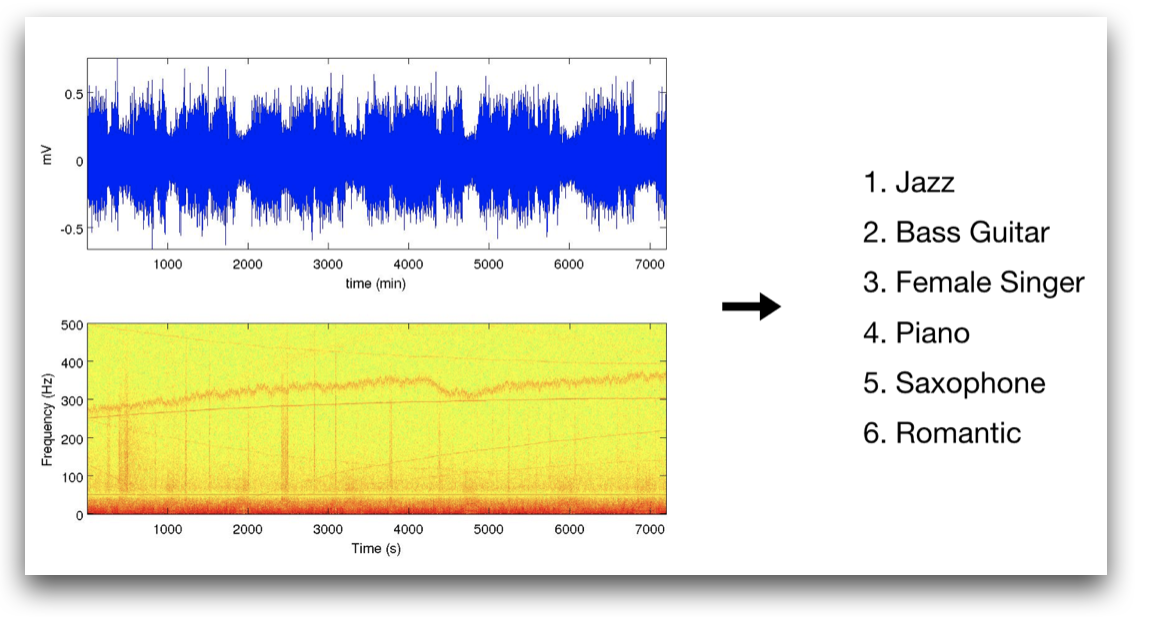
Automatically Tagging Audio/Music Clips with Descriptive Tags
Advised by Alexandros Potamianos
We embedded audio clips and the corresponding descriptive tags into the same multimodal vector space by representing tags and clips as bags-of-audio-words. In this way, we can easily (1) annotate audio clips with descriptive tags (by comparing audio vectors to tag vectors), or (2) estimate the similarity between audio clips or music songs (by optionally enhancing audio vectors with semantic information).
[Multi-Learn@EUSIPCO '17 paper]
Grounding Natural Language to Perceptual Modalities
Advised by Alexandros Potamianos
We created multimodal word embeddings as an attempt to ground word semantics to the acoustic and visual sensory modalities. We modeled the acoustic and visual properties of words by associating words to audio clips and images, respectively. We fused textual, acoustic, and visual features into a joint semantic vector space in which vector similarities correlate with human judgements of semantic word similarity.
[INTERSPEECH '16 paper] [Multi-Learn@EUSIPCO '17 paper]
Urban Soundscape Event Detection and Quality Estimation
Advised by Theodoros Giannakopoulos
We collected hundreds of recordings of urban soundscapes, i.e., sounds produced by mixed sound sources within a given urban area. We developed Machine Learning algorithms that analyze audio recordings to (1) detect acoustic events (e.g., car horns, human voices, birds), and (2) estimate the soundscape quality in different urban areas.